
BLOG
Machine Learning: Vorteile und Anwendungen für Unternehmen
Künstliche Intelligenz, insbesondere Machine Learning in Unternehmen, wird sich zur einflussreichsten Technologie entwickeln, Branchen und Bereiche von Grund auf neu zu transformieren, die bereits jetzt schon im Fokus der Digitalisierung stehen.
Max. Lesezeit 13min
Mit der Verbreitung des Internets, der wachsenden Online-Präsenz und den angeschlossenen Geräten, die eine große Flut an digitalen Informationen erzeugen, verlassen sich Unternehmen zunehmend auf Algorithmen, um ansonsten weitreichende Probleme mit guten Garantien für eine Lösung zu lösen. Daten sind der Beschleuniger für unsere Informationsgesellschaft. Deshalb sind neue Technologien und maschinelle Lerntechniken der Schlüssel, um mit der neuen Informationsfülle in komplexen Zusammenhängen fertig zu werden.
Machine Learning – was ist das?
Doch wobei handelt es sich bei Machine Learning? Machine Learning als Teilgebiet der Künstlichen Intelligenz (KI) bedient sich Algorithmen und Modellen, mit denen Computer Aufgaben ohne ausdrückliche Anweisungen ausführen können. Dadurch können Aussagen getroffen werden auf Basis menschlicher Lernfähigkeiten, die dem System helfen, sich durch diese Erfahrung automatisch zu verbessern und eine genaue Ausgabe basierend auf neuen Informationen zu liefern. Vereinfacht gesagt lässt sich festhalten, Machine Learning findet Antworten auf geschäftsbezogene Probleme. Es ist ein Datenanalyseprozess, der Algorithmen nutzt, um iterativ aus den vorhandenen Daten zu lernen und Computern zu helfen, versteckte Erkenntnisse zu finden, ohne dafür programmiert zu sein.
Machine Learning kann Unternehmen helfen, durch den Einsatz dieser Technologien datengesteuerte Entscheidungen zu treffen, die sich durch Einsparungen und mehr Umsatz bemerkbar machen. Darüber hinaus helfen Machine Learning-Algorithmen, Risiken und Betrug auszuschließen, sichere Prozesse zu gewährleisten und die Kundenzufriedenheit zu verbessern. Umfragen zeigen, dass es Anwendungsfälle für Machine Learning über alle Branchen und alle Ebenen von Unternehmen hinweg gibt. Künstliche Intelligenz und insbesondere Machine Learning wird innerhalb der nächsten Jahre nicht nur einen erheblichen Einfluss auf die Gesellschaft haben, sondern vor allem auch für die eigenen Geschäftsbereiche.
Anwendungsfälle von Machine Learning in Unternehmen
Machine Learning angewandt werden, um Kundengespräche im Zusammenhang mit einem Produkt zu verfolgen und zu verstehen. Es kann sogar den Algorithmus anwenden, um die von den Kunden erwartete Funktionalität und Ausstattung vorherzusagen. Darüber hinaus kann ein Unternehmen Machine Learning nutzen, um bessere Beziehungen zu seinen Kunden aufzubauen. Der Algorithmus des maschinellen Lernens kann die Kundenanfragen leicht erkennen und an das entsprechende Team senden. Es wird den Prozess der Lösung der Probleme der Kunden beschleunigen und ihnen schnell Antworten liefern.
Bei der Erstellung von digitalen Services können Unternehmen Machine Learning nutzen, um Kunden zu ermöglichen, Produkte oder Informationen schneller zu finden. Ein spezifischer Algorithmus trägt dazu bei, dass die Kunden relevante und qualitativ hochwertige Informationen rechtzeitig erhalten. Darüber hinaus hilft die neue Technologie den Kunden, Produkte nach ihren Bedürfnissen und Vorlieben auszuwählen.
Lernalgorithmen können in der Finanzindustrie eingesetzt werden, um automatisierte Handelsstrategien zu entwickeln. Sie können verwendet werden, um Muster zu erkennen und Handelsentscheidungen auf der Grundlage von Daten zu treffen. Die anderen potenziellen Anwendungen sind die Schaffung von Kreditbewertungsmechanismen durch die Suche nach Mustern externer, interner und wirtschaftlicher Faktoren, die die finanzielle Leistungsfähigkeit von Unternehmen beeinflussen. Ebenso können diese Techniken auch angewendet werden, um den Kunden eine relevante automatisierte Anlageberatung zu bieten.
Die Geschwindigkeit, mit der Machine Learning relevante Daten identifiziert, ermöglicht es Unternehmen, geeignete Maßnahmen zum richtigen Zeitpunkt zu ergreifen. So optimiert Machine Learning beispielsweise das beste Folgeangebot für die Kunden eines Unternehmens. So kann der Kunde zu einem bestimmten Zeitpunkt das richtige Angebot sehen, ohne dass ein Mitarbeiter für die individuelle Betreuung oder Angebotserstellung Zeit aufwenden musste. Machine Learning ermöglicht es Unternehmen, die Daten über vergangene Verhaltensweisen oder Ergebnisse zu analysieren und zu interpretieren. Auf der Grundlage der neuen und unterschiedlichen Daten können daher bessere Vorhersagen über das Kundenverhalten getroffen werden.
Angriffe auf IT-Netze treten in der Regel in Echtzeit auf, ohne vorher gewarnt zu werden. Damit Unternehmen die Netzwerksicherheit aufrechterhalten können, muss jedes verdächtige Netzwerkverhalten proaktiv identifiziert werden, bevor das Eindringen zu einem vollwertigen Sicherheitsangriff, Datenverlust und Ausfällen führt. Machine Learning-Algorithmen helfen, das Netzverhalten in Echtzeit auf Anomalien zu überwachen, so dass proaktive Maßnahmen automatisch ausgeführt werden.
Wie Unternehmen Machine Learning implementieren
Mit der Einführung ihrer Cloud Machine Learning-Plattformen durch Google, Amazon und Microsoft Azure konnte das Thema künstliche Intelligenz in den letzten Jahren an Bedeutung gewinnen. Dabei bestehen verschiedene Ansätze Machine Learning im Unternehmen einzuführen. Die Kosten für die Datenspeicherung sind so dramatisch gesunken, so dass Unternehmen auf große Datenmengen zugreifen können, die Muster profitablen Geschäftswissens verbergen und mit Hilfe von Machine Learning-Technologien enthüllt werden. Einige Unternehmen verwenden Cloud-basierte Tools und Systeme von Drittanbietern, andere verwenden Anwendungen mit integrierten Machine Learning Funktionen. Viele Algorithmen und Frameworks sind über Open-Source-Kanäle zugänglich. Diese bereits bestehenden Ressourcen ermöglichen es Unternehmen, Machine Learning zu nutzen, ohne im Voraus in die erforderliche Infrastruktur investieren zu müssen. Die Technologie ist bereits ausgereift und Unternehmen können die Vorteile nutzen.
Diese Vorteile können auf eine Vielzahl von Anwendungsfällen angewendet werden, insbesondere wenn Daten im Mittelpunkt des Serviceangebots stehen. Die Technologie ersetzt den manuellen Betrieb im Marktsegment Unternehmen schnell, und sowohl kleine und mittlere als auch große Unternehmen sind gut positioniert, um die Vorteile von Machine Learning-Lösungen zu nutzen.
Digitale Produkte, die lernfähig sind
Umsetzung von Machine Learning Anwendungen
Künstliche Intelligenz (KI) und Machine Learning (Machine Learning) sind die Technologien mit dem größten Potential, unsere Zukunft völlig neu zu gestalten.
Machine Learning liefert uns Werkzeuge, um Geschäftsprozesse zu rationalisieren, die Entscheidungsfindung zu verbessern und die Genauigkeit von Aufgabenlösungen zu erhöhen, bei denen Menschen fehleranfällig sind. Das alles allerdings unter der Einschränkung, dass die geforderten Ergebnisse nicht sofort verfügbar sein müssen, denn Algorithmen müssen Lernen und der Verbrauch an Rechenleistung kann immens sein. Doch nicht alle Machine Learning-Anwendungen und -Projekte werden von Beginn an erfolgreich sein. Viele Unternehmen müssen erst die erforderliche End-to-End-Pipeline aufbauen, um die kontinuierliche Schulung von Modellen zu unterstützen.
Die Bedürfnispyramide – Voraussetzungen für den Erfolg von Data Science und Machine Learning
Wenn Sie mit der Data Science Bedürfnispyramide nicht vertraut sind, beschreibt Monica Rogati (ehemalige VP of Data bei Jawbone und LinkedIn Data Scientist) die verschiedenen Voraussetzungen für den Erfolg mit Data Science und Machine Learning. Die Festlegung der grundlegenden technischen und kulturellen Anforderungen wird wahrscheinlich viel Zeit in Anspruch nehmen. Wenn es um das Toolset geht, werden umfassendere und „End-to-End“-Lösungen wie Googles Tensorflow und AWS Machine Learning attraktiv. Es ist jedoch wahrscheinlich, dass Unternehmen Kompromisse eingehen müssen, um sich an ihre Cloud-Strategie anzupassen und verschiedene Tools einzusetzen, bis der Markt reif ist.
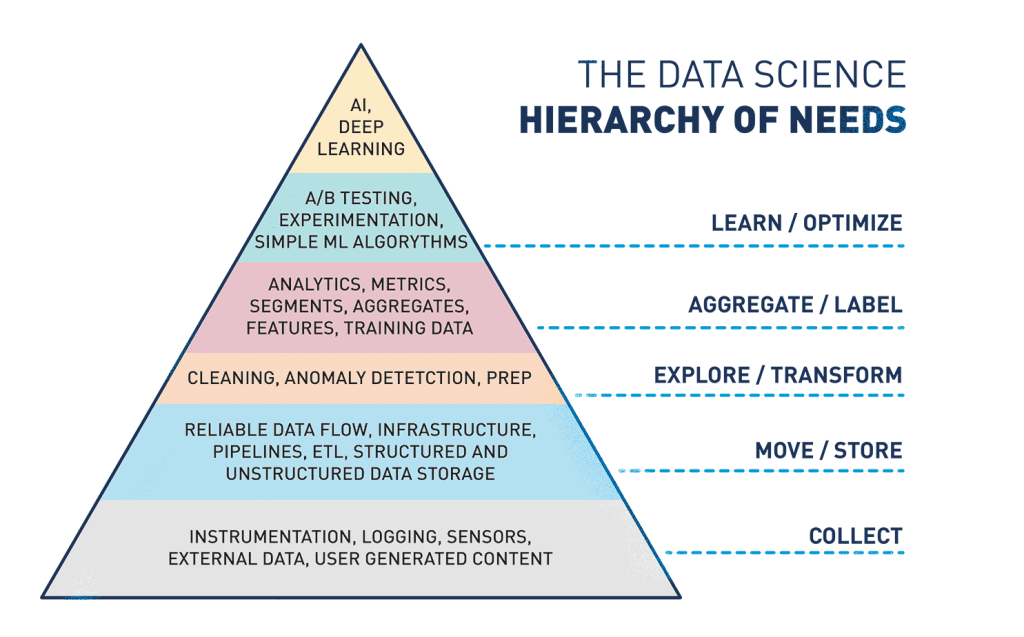
Quelle: Hackernoon https://hackernoon.com/the-ai-hierarchy-of-needs-18f111fcc007
Für die Implementierung von Machine Learning müssen zuerst organisatorische Themen geklärt werden, sowie das Rekrutieren oder die Ausbildung von Spezialisten. Darüber hinaus gibt es noch viele Maßnahmen, die ergriffen werden müssen, um Investitionen in Machine Learning zu maximieren und Funktionalitäten schnell in Frontends und digitale Dienste zu integrieren.
Wie können also heute Apps und digitale Dienste entwickelt werden, die es uns ermöglichen, Machine Learning morgen am effizientesten einzusetzen? Bereits beim Aufbau neuer digitaler Dienste kann Machine Learning bei der Konzeption berücksichtigt werden, so dass die Implementierung später einfacher wird und mehr Wirkung zeigt. Das ist der Ansatz:
1. Erstellung von minimalen Machine Learning-Modellen
Das Ziel jeder digitalen Lösung ist es, dem Anwender einen Mehrwert zu bieten. Ziel sollte es daher sein, mit möglichst geringem Aufwand (Zeit und Ressourcen) einen Mehrwert für die Anwender zu schaffen. Wenn ein Minimum Viable Product (MVP) den Benutzern ohne Machine Learning keinen Mehrwert generieren kann, ist es wahrscheinlich, dass es damit auch keinen Mehrwert generiert.
Wenn ein MVP aus irgendeinem Grund keinen Mehrwert generiert, ohne eine Art von KI- oder Machine Learning-Fähigkeit (z.B. Bilderkennung) zu nutzen, dann sollte die Verwendung von Cloud-APIs in Betracht gezogen werden, welche die grundlegendsten Funktionen abdecken. Services von AWS, Microsoft Azure oder Google bieten möglicherweise nicht die höchste Genauigkeit für Ihren Anwendungsfall, aber sie sollten ausreichen, um den Anwendungsfall zu validieren und eine größere Investition in den Aufbau und die Schulung Ihres eigenen Machine Learning-Modells zu rechtfertigen. Es gibt auch Open-Source-Projekte, die Sie für den Einstieg in die gängigen Machine Learning-Aufgaben verwenden können. Letztendlich können diese Dienste oder Open-Source-Projekte die Anforderungen vollständig erfüllen.
2. Sammeln von Daten und Ereignissen
Da Daten die digitale Währung des maschinellen Lernens sind, muss sichergestellt werden, dass Ihr digitales Produkt alles sammelt, was für den Anwendungsfall relevant sein könnte. Ein Paradebeispiel, das in jedem digitalen Produkt gesammelt werden sollte, ist die Nutzeranalyse. Wenn Sie in der Lage sind, Informationen darüber zu sammeln, wie Nutzer mit Ihrer Anwendung interagieren, welche Aktionen bestimmte Nutzersegmente ausführen, dann sind das Daten, die in Zukunft möglicherweise dazu verwendet werden können, die Nutzerfreundlichkeit durch maschinelles Lernen zu verbessern.
Alle Analysetools, die Sie verwenden, sollten nicht nur Daten sammeln, sondern vor allem auch in einem strukturierten, sauberen und standardisierten Format exportierbar sein. Diese Nutzeranalysen werden nicht von großem Nutzen sein, wenn man sie nicht zum Trainieren von Modellen des maschinellen Lernens verwenden kann. Stellen Sie außerdem sicher, dass Sie über die Möglichkeit verfügen, benutzerdefinierte In-App-Ereignisse zu erstellen. Dies gibt Ihnen die Möglichkeit, dass alle richtigen Metriken gesammelt werden, die spezifisch für Ihre Anwendung sind.
Eine weitere zu berücksichtigende Tatsache ist die Datenverarbeitung und deren rechtlichen Rahmenbedingungen der Analytics Lösung. Viele Analysetools sind SaaS-Modelle und ermöglichen Ihnen den Zugriff auf Ihre Daten, deren Speicherung und Verarbeitung aber an Standorten vollzogen werden kann, deren rechtlichen Rahmenbedingungen nicht immer eindeutig oder konform sind. Viele schätzen die Tatsache, dass sie die vollständige Kontrolle über ihre Daten haben und diese nicht in einer Drittanbieterumgebung verwendet oder gespeichert werden, sondern in ihrer eigenen Instanz.
3. Vorhandene Daten aggregieren und strukturieren
Da viele Unternehmen bereits über einen Schatz an Daten verfügen, die in Datenbanken und anderen Silos der Unternehmens-IT (CRMs, ERPs, etc.) verpackt sind. Häufig sind die Daten auch über verschiedene Systeme verteilt und um den vollständigsten Datensatz zu erhalten, kann es notwendig sein, Daten aus mehreren Quellen zu erhalten und bei Bedarf zu orchestrieren. Oftmals handelt es sich dabei um eine Mediendatei oder einfach um Informationen, die in der Vergangenheit nicht gespeichert wurden, aber für den aktuellen Anwendungsfall relevant sind.
Bei der Integration von Datenquellen ist es einfach, Daten aus mehreren Quellen zu aggregieren und zu strukturieren. Ein beliebtes Beispiel ist die Erstellung einer vollständigeren Sicht auf den Kunden durch die Kombination von Daten aus mehreren CRMs oder ERP-Systemen. Auf diese Weise sind die Daten nahezu bereit für Ihre Machine Learning-Pipeline. Sie können Attribute hinzufügen, wenn zusätzliche Labels oder Ergebnisse von Ihrem Machine Learning-Modell geschrieben werden sollen. Auf diese Weise können Sie Datensätze anpassen, ohne Änderungen in Ihren bestehenden oder unternehmensweiten IT-Systemen vornehmen zu müssen.
4. Kennzeichnung und Export von Daten
Da das Hinzufügen von Labels und Attributen zu Ihren Datensätzen einfach ist, ist es an der Zeit, mit der eigentlichen Kennzeichnung der Daten zu beginnen. Dies kann manuell oder automatisch erfolgen. Unabhängig davon, ob der Kunde beginnt, seine Daten zu kennzeichnen, hat er immer die Möglichkeit, alle Daten über unsere REST-API zu exportieren.
Der Zugriff auf die Daten über eine API ist unerlässlich, da diese Ihnen ermöglicht, den Datenexport zu automatisieren, so dass Sie leicht auf den neuesten Datensatz zugreifen und ihn zum Trainieren neuer Modelle verwenden können. Da Kunden ihre Daten bereits aus mehreren Datenquellen integriert oder um zusätzliche Attribute oder Datenmodelle ergänzt haben, werden die Daten mit Labels strukturiert und sind schulungsreif. Die Extraktion spezifischer Datensätze erfolgt ebenfalls einfach über die unterstützte Abfragesprache.
5. A/B-Tests beim Einsatz neuer Modelle verwenden
Bei der Bereitstellung von Machine Learning-Modellen ist es wichtig, dass Sie nicht 100% Ihrer Nutzer für zu einem neuen Modell zuordnen, da Fehler oder falsche Ergebnisse jeden betreffen würden. Es gibt mehrere Ansätze, wie Sie A/B-Tests implementieren können, und im Idealfall ist es dann einfach, zur alten Version zurückzukehren oder das neue Modell bei allen Ihren Nutzern einzuführen.
6. So schnell wie möglich mit der Erfassung weiterer Daten beginnen, wenn diese benötigt werden
Daten sind der Lebensnerv des maschinellen Lernens und Ihre Daten können den Erfolg oder Misserfolg Ihrer Machine Learning-Aktivitäten bestimmen. Bei der Erstellung und Schulung von Modellen kann der Zugriff auf zusätzliche Attribute der Schlüssel zur Verbesserung des Modells sein.
Machine Learning-fähige Produkte umsetzen
Wenn Sie also planen, ein digitales Produkt auf Basis von Machine Learning zu entwickeln, beginnen Sie mit einem MVP und stellen Sie sicher, dass Sie den Nutzern einen Mehrwert bieten können. Es gibt nichts Schlimmeres, als eine riesige Investition in ein digitales Produkt mit – aber auch ohne – Machine Learning zu tätigen, das den Nutzern überhaupt keinen Mehrwert bietet.