

OCR technology helps us digitize text and makes our lives much easier. Read on to learn what you need it for and how it works.
What is optical character recognition (OCR)?
The OCR process is a text recognition process. Its aim is to recognize letters in images. To accomplish this, the OCR process first converts a document into a black and white image, i.e. a raster graphic. This is followed by a pattern recognition process.
How optical character recognition helps us every day
Let’s get practical. There are many use cases for OCR. For example, a user might want to do more than just read a contract or an invoice as a PDF. If these PDFs contain selectable text
- that can be copied into another document or
- the PDF is already searchable,
character or text recognition has often already taken place. We have all experienced this, but it should not be taken for granted. This is because PDFs often consist only of image data. Text recognition is necessary because document-generating input devices such as scanners, fax machines or digital cameras only deliver pixel-based images (JPEGs, PNGs, TIFFs etc.) embedded in a PDF. Optical character recognition transforms these into characters and character strings through pattern recognition.
In summary: Character recognition and the conversion of recognized characters into text is the main task of optical character recognition. There are many use cases for OCR, and they are all very helpful.
Where is OCR used?
Optical character recognition makes many things possible, especially in the context of automated document management. Automatic text recognition provides a valuable service here. For example, OCR programs help with the extraction of metadata, which can later be used for indexing. Other uses are also possible. For instance, the recognition and extraction of invoice data as the basis for the three-way match. OCR is essential for the entire process of document capture.
How does it work?
The process for character recognition is based on raster graphics. These are dots of different colors arranged in rows and columns, i.e. the individual pixels. OCR (optical character recognition) is a technology used to convert printed or handwritten text into machine-readable text. The OCR process takes place in several steps:
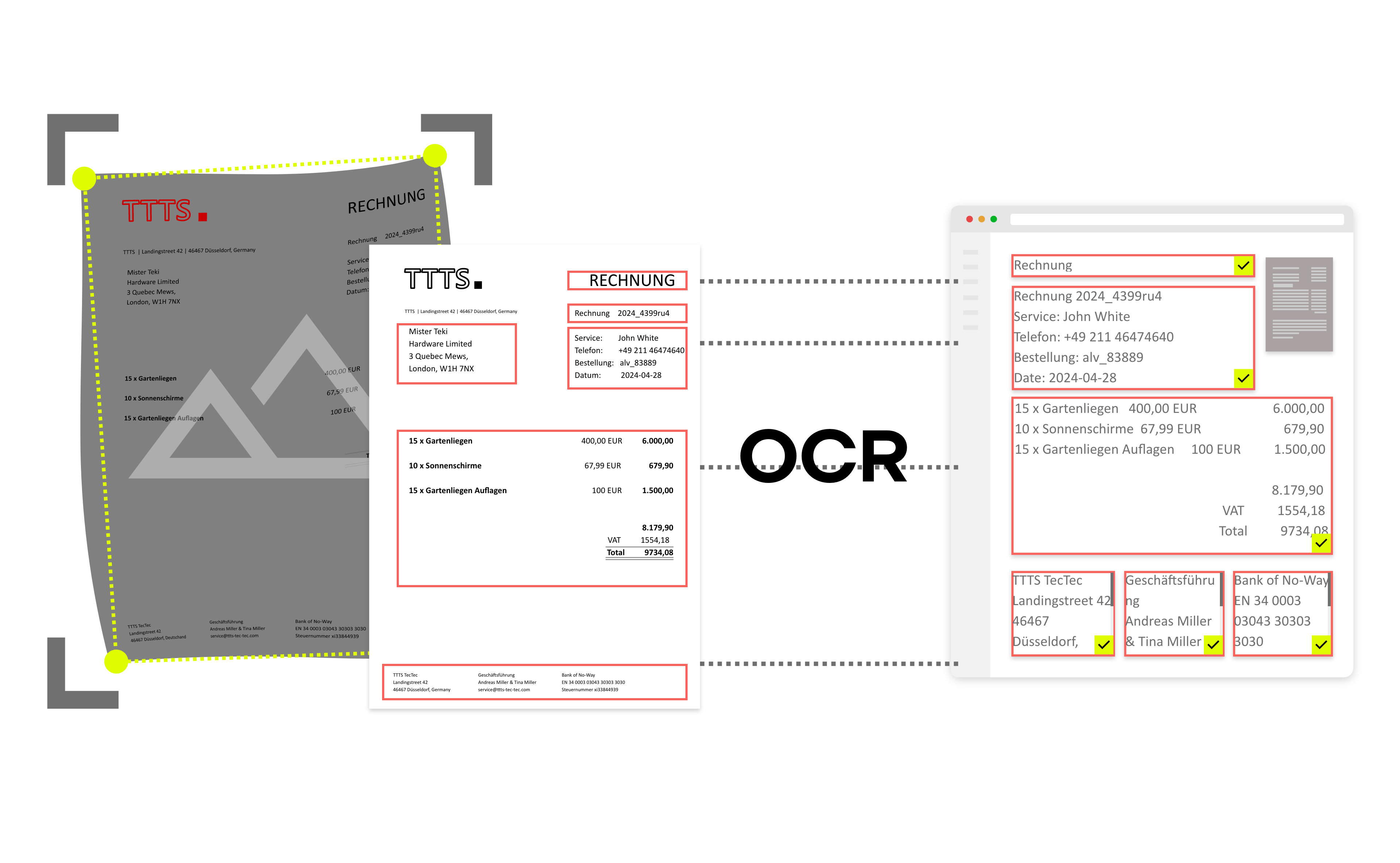
Optical Character Recognition is a technology used to convert printed or handwritten text into machine-readable text, and the OCR process involves several steps:
- Image capture: The first step in Optical Character Recognition is to capture an image or scan of the text document.
- Pre-processing: The captured image is pre-processed to prepare it for OCR and text recognition. This can include removing noise, aligning text and adjusting the contrast.
- Segmentation: The text is divided into segments such as lines of text, words or letters to enable more accurate OCR recognition.
- Pattern recognition: In this step, the OCR algorithm analyzes the shapes and patterns in the segments to identify letters, numbers and symbols.
- Text reconstruction: The patterns recognized by OCR are combined into a reconstructed text.
- Text output: The reconstructed text data is available as output and can be saved in a digital format or processed further.
Optical character recognition: A powerful technology for text recognition
Even if IT acronyms like OCR often seem opaque, the technologies they stand for have tremendous impact. In everyday life, this technology helps us capture, edit and use text from images or scans. Optical character recognition saves us a lot of time and effort. It is no longer necessary to type in texts or read through them paragraph by paragraph to find specific information. Anyone who uses the PDF viewer Adobe Acrobat already uses the built-in optical text recognition. In professional document management and document-intensive processes, OCR replaces manual data entry. Documents can be captured, classified, extracted and validated automatically. This yields significantly shorter processing times and improved data quality. This is accomplished using OCR engines, such as ABBYY Finereader or Tesseract.

