

Last updated on March 2026
BLOG
Microservices vs. Monolith: A Shift in Software Development
Not a day goes by we don’t read or hear about digitization and Cloud solutions for companies. But even if both subjects are prominent in the public perception, I often find that both terms are used almost arbitrarily.
Max. Reading time 30min Published September 9, 2019
The most important points summarized
- Unlike monoliths, which are built as a single, cohesive unit with a massive code base, microservices consist of a suite of small, independent services that communicate via APIs.
- Microservices are ideal for small teams and projects because they incur lower overhead costs and facilitate the management of cross-functional tasks, such as security.
- This model provides independent scalability and technological freedom. Decoupling services enables faster development cycles and greater fault tolerance.
- However, microservices require a more complex infrastructure, such as Docker or Kubernetes, as well as sophisticated monitoring. Errors are more difficult to find in a network of hundreds of services.
- The choice depends on the context. Monoliths are ideal for new products and proof of concept, while microservices are advantageous when systems grow quickly and the independent provision of functions is necessary.
Microservices are an approach to software development, and originate from the DevOps movement. After all, unlike monolithic applications, microservices are the basis for DevOps and continuous delivery methods. In an ever-changing world of business, applications and programs are required to adapt quickly to the user requirements. And that is the precise strength of microservices. That’s because microservices support loosely-connected architectures and the independent scaling of the individual components. In this respect, they differ from the traditional, monolithic software development.
Microservice vs. monolith: the difference metaphorically illustrated
Let us address the matter with an image. As with house building, there are a variety of ways in which IT systems are designed and built. This allows for a clear illustration of the difference between a microservice and a monolith.
The monolithic approach
To simplify matters, imagine a detached family house: Depending on the requirements, the architect is able to build a classic house in a rectangular shape. The architecture is predetermined, everything has its fixed, pre-defined place. The windows, doors, walls, cellars and floors… – a monolithic system, a rigid structure. If the residents want to change something after several years, they are faced with a variety of problems: Can I really tear down this or that wall or build new walls in the attic and thus rooms for various purposes, for example, or would I put the structure at risk? In software development, this concept corresponds to the monolith (see below).
The micro-service approach
However, a homeowner can also opt for a flexible, modular design right from the start. And they do so in anticipation that their needs will change in the future. In the first step, the builder considers building the house from individual containers. As soon as his initial thoughts, he remembers not to make use of rectangular containers – but of containers in a hexagonal format, similar to the honeycombs in a beehive. The reason quickly becomes clear. Building a house using hexagonal containers, for example, means that the builder doesn’t just stack additional containers side by side or on top of one another. On the contrary, for example, he can remove a container from the third floor later without this adversely affecting the fourth or fifth floor. This approach is equivalent to a microservices architecture.
This very simple representation can also be applied to IT and software systems. The classic house would roughly correspond to the monolithic architecture, the container house to the microservice architecture. Both have advantages and disadvantages.
Monolithic software architecture and microservices: differences
A traditional monolithic architecture is configured as a single large-scale system, and is usually based on a code. It is usually provided in its entirety – which means that if any of the details are changed, the entire architecture has to be edited and made available in closed form. Microservices, on the other hand, are apps that are built as a suite of small services, all of which have their own code base. These services are built around specific functionalities and can be provided independently of each other. Therefore, in the case of detailed changes, it is only necessary for the corresponding micro service to be changed, and not the entire app.
This has decisive advantages, which is noticeable, for example, in the speed of the provision and development in the context of continuous delivery. In reality, however, microservices also increase the complexity, making them more difficult to manage, and topics such as IT governance and compliance are frequently left unresolved.
Therefore, companies and IT departments that take a conventional approach tend to start with a traditional monolithic architecture, especially when the team is very small and the time constraints are very tight. But that isn’t always the right decision. The right choice depends entirely on the type of project. To understand this better, it is firstly necessary to define both options clearly, and to list their advantages and disadvantages.
Monolith: what is meant by this?
A monolithic application is built as a single and coherent unit. It usually consists of three separate parts: a database, a user interface and a server-side application. It handles requests, executes domain-specific logic, retrieves data from the database, completes the corresponding updates and manages the HTML views that are sent to the browser.
In a monolithic logic, the frontend logic on the user side, the background processes and the server logic etc. are all stored in the same massive code base. When developers make changes and updates, they have to build and deploy the entire stack, starting from scratch. That does not mean that a monolith is an outdated architecture that should be consigned to history, however. A monolith is ideal for certain applications: for a small application, for instance, where it would be far too time-consuming to split it into individual microservices.
Advantages of monoliths
- Overlap
- Lower operational overhead costs
- Performance
Disadvantages of monolithic applications
- Fixed coupling
- Increased complexity
- Reduces productivity
- Changing code base is complicated
- If one function fails, the entire application fails
- Inefficient horizontal scaling
- Slower development time
monolith Advantages in detail
- The biggest advantage of a monolithic architecture is that there is a lot of overlap in most apps – such as logging or security functions – and these are easier to handle in monolithic architectures. If everything runs on the same app, then it is easy to connect the components.
- Lower operating overhead costs: as it is a single, large-scale application, the logs, monitoring and tests only have to be set up for one application. This means that the app is generally easier to provide.
- Performance: there may be advantages, as there is no communication between the individual services.
monolith Disadvantages in detail
- Fixed coupling: monolithic architectures tend to interlock and entangle more tightly as the application evolves, making it difficult to isolate the individual services for one purpose, such as independent scaling or code maintenance.
- Higher complexity: monolithic architectures are much more difficult to understand, as there are always dependencies and effects that cannot be identified clearly by focusing on a specific server or controller.
- As a monolithic application grows, so does the associated code base, which overburdens the development environment each time the application loads. This reduces the productivity of the developers.
- As the application runs on EAR/JAR/WAR, for example, it is difficult to change the technology afterwards. Changing the code base of a monolith is complicated because it is always difficult to predict how this will affect the functionality of the entire monolithic application.
- If a single function of the monolith or a single component fails, the entire application fails. If an application contains functions such as payment, login and history, for example, and only one of the functions starts to use more processing power, then this will hinder the performance of the entire application.
- Those who want to scale monolithic applications can only do this by distributing the same EAR/JAR/WAR packages on additional servers. This is known as “horizontal scaling”. Each copy of the application on additional servers uses the same number of underlying resources, making it an inefficient design.
- Monolithic architectures influence the development as well as the deployment of the applications. When applications grow, it is even more important to break the applications down into smaller components. As everything is so tightly interrelated, developers are unable to work independently on monolithic architectures or provide only their own modules. Rather, they are dependent on others and this slows down the development time.
- Be it new functions, user interfaces or technology interfaces, software must provide innovations quickly and easily without negatively affecting the existing applications. This is not a simple task, even for software manufacturers, because existing software in companies is often still developed as a monolith. In other words, a centrally installed program which provides all modules as a whole. And the larger the monolith, the riskier it is to provide new functions quickly.
With these disadvantages in mind, let us now take a look at microservices. In this respect, it is necessary to answer the questions of why microservices, in particular, offer more flexibility than monoliths and the factors that are required for the successful use of microservices – without ignoring the disadvantages of microservices.
Definition of Microservices
Let us approach the answer colloquially, after all, we want to explain the idea of microservices in a simple and comprehensible way: Microservices are an architectural concept, a paradigm of application development. This concerns the way in which the applications are developed. Extensive application software, which is implemented conceptually via microservices, consists of smaller, independent programs. Each of these programs completes precisely one task – true to the Unix philosophy: “Do one thing well.” A philosophy that has been pretty successful for the world of software, it has proven itself in userland/userspace in many incarnations and manifestations up to the present day – since the early 1970s, from the origins of Unix and subsequent BSDs, via Nextstep and Darwin, through to Linux.
Microservices are not necessarily small, or even “micro”. Although they are usually smaller than classic monoliths, their complexity or code base can be quite extensive. The microservice architecture is an approach to providing an application that consists of a set of smaller services, each of which has its own processes and communicates via interfaces (API). These services are built around capabilities that an organization is required to provide, and are provided independently through automated deployment mechanisms. At the same time, the management of these services is centralized and reduced to a minimum.
These programs then communicate with each other as microservices via well-defined APIs (interfaces). As interfaces ideally behave agnostically towards the programming languages that are used, this provides development teams with new scope for action. At the same time, the microservices paradigm also forces the individual microservices to be independent of each other. That has consequences: A single microservice will then function independently of all the other services or not at all. But that doesn’t matter. After all: If the latter occurs, this failure will not bring all the other services to a standstill. It’s an inconvenience, but it’s good enough. A software system that conceptually consists of many of these microservices can rightly be called a microservices architecture.
Advantages of microservices
- Better organization
- Decoupling
- Performance
- Fewer errors, High rate of fail-safety
- A smaller code basis means less complexity within the individual microservices.
- The communication workload between the individual project teams is reduced.
- Continuous delivery
- Better scalability: Individual services can be scaled several times
Disadvantages of microservices
- Complexity of the entire system of microservices
- Sophisticated deployment of the services
- Unexpected latency between the microservices in the distributed system
- Each microservice is an independent system; this also applies to the deployment process; resources must be kept available; high-cost
- High workload for the migration of old systems to the new microservice architecture
- Convergence of different services
- Higher operational overhead costs
- Demanding monitoring
- Costly troubleshooting
Microservices Advantages in detail:
Where flexibility and speed are currently important in the world of business, a microservice architecture has a special role to play. The initial workload required to plan, develop and finally roll out a microservice architecture should not be underestimated. It is certainly greater than in comparison with a monolithic application. However: Once the architecture is in place, many of the advantages of microservices can be used. In this respect, trying out new business ideas “just like that”, for example, no longer presents a company with problems.
On this basis, it would be easy to accelerate the process of putting business ideas or goals to an initial reality test via so-called “minimum viable products” (MVPs). This is one of the advantages of microservices. The same applies to subsequent, rapid iterations of error corrections, adjustments and improvements to the first MVPs as a microservice – which is ideal for service-driven architectures. This is just one of the advantages of microservices though. Now, let us take a look at what other advantages microservices offer and why this is the case.
- Superior organization: microservice architectures are typically better organized because each microservice has a specific task and is not required to deal with the other components.
- Decoupling: decoupled services are easier to disassemble and reconfigure to serve the purpose of different apps (such as the authorization and streaming service, for example). They also allow for the faster, independent delivery of individual parts within a bigger, integrated system. Each of these microservices is self-contained and has only the one task for which it is intended. That way, it is very simple to add additional microservices without endangering the stability of the entire program. The development of services is also much simpler, because the complexity is significantly reduced.
- Performance: in the right circumstances, depending on how they are organized, microservices can deliver performance benefits, especially because heavily used services can be isolated and scaled independently from the rest of the app. While in a monolith, every function is only available once and only scales with the entire monolith, microservices can be available as often as desired. An example here would be a search service. If you determine that the users of the program search a great deal, then multiple instances of precisely this service can be made available. However, it is not necessary to start other services multiple times, but only those which you need multiple times. This ability not only makes the software extremely powerful, it also leads to it being economically very efficient.
- Fewer errors: microservices enable parallel developments, because boundaries exist between different parts of the system that are difficult to cross. This makes it harder to do the wrong thing, specifically, to connect parts that shouldn’t be connected, or to connect things that should be connected, albeit too closely
Microservices Disadvantages in detail:
- The biggest disadvantage of microservices is in the convergence of the different services: those creating a microservice architecture will find that many of the approaches overlap. One solution is for the interfaces to run completely through a separate layer which is responsible for the processes. In monolithic architectures, the traffic often runs through an outer service layer for exactly these overlaps; the cost of this work can be delayed for much longer with monolithic architectures, however, i.e., until the project is much more advanced and mature.
- Higher operating overhead costs: microservices are often be deployed on their own virtual machines or in containers, which frequently increases the costs. These tasks are often automated.
- Time-consuming monitoring of the microservices: those who launch a classic app in microservices or build a completely new microservice system will have many more services to monitor. The services are active on different machines and/or in different containers; use different technologies and/or languages, and can sometimes have their own version control. It’s pretty clear that in this case, there is an urgent need for centralized monitoring and logging.
- Costly troubleshooting: assuming that a microservices network consists of several hundred microservices that interact with each other, it isn’t easy to find the cause of an error, which may potentially be distributed over several services. It is therefore necessary to have a centralized tool that detects these problems from their origin.
In general, considering the advantages and disadvantages of both approaches makes sense. However, these alone are not sufficient as a decision-making basis for companies. On the contrary, to ensure that they choose the right approach for their business, companies should ask themselves some fundamental questions.
Examples of microservices – specific illustration of the division of labor
Let us take the example of a website for a parcel and letter-sending service. On this website, you can find numerous examples of microservices:
- Tracking of the shipment,
- Calculation of postage fees,
- Online franking,
- Required location for receiving the shipment etc.
And all, of course, as services for private customers and business customers. But just because the tracking of the shipment fails, for example, does not mean that all the other microservices are affected and are no longer available. These services are good examples of a microservice architecture. Many of the services can be accessed via a rest API, for example; it goes without saying that microservices can also be used via an app for iOS and Android. These are all signs that could point to a microservices architecture. Other practical examples of Microservices are used by the companies Twitter, eBay, Spotify, Netflix and Zalando etc.
Monolithic architecture – traditional but not outdated
To be able to understand microservice architectures at all, it is firstly worthwhile to take another look at standard, monolithic architectures. Their structure can be thought of as one big application, a block where all the necessary code is collected. Although the functions provided are modularized, they are neither independent of each other nor of the entire block. The monolith only exists as a bloc. The software is written, compiled and deployed as a unit, i.e. distributed on user PCs or servers. A particularly clear example is the Amazon web shop of the past. This was realized several years ago as a monolithic application (300 to 500 MB in size, compile time up to 10 hours). This wasn’t easy to maintain and it wasn’t easy to add new features, not to mention the deployment.
Microservices or monolith: choosing the right approach
1. Is the company operating in a familiar territory?
Those who are already well-versed in a field and know the corresponding benefits are able to experiment directly with microservices. Those moving in completely unknown territory and who have no previous experience in the field in which they are working are often better off with monolithic architectures.
2. Is the team well-prepared?
Does the team already have experience with microservices? And are microservices the right approach when the team continues to grow? Evaluating these factors is essential for the success of a project. If a team is already well-prepared, it makes sense to start directly with the microservices, so that the team members get used to the rhythm of the development in a microservices environment – and right from the start.
3. What is the infrastructure?
For microservices to work for a project, a cloud-based infrastructure is necessary. With modern cloud services, such as Google Cloud and Amazon AWS, providing the service has become much easier, as it isn’t necessary to either purchase or to ensure the availability of the entire server base.
4. Evaluating the risk
Microservices are often ambitious, which means they pose a business risk if teams with limited experience embark on the use microservices, or if their use is not appropriate.
5. The context is crucial
The individual context and scenario are of decisive importance in determining whether a monolithic architecture or microservices should be chosen. Companies should be aware of this before they decide on the architecture that is appropriate to their situation.
A monolithic architecture makes sense if…
- The team is still in the start-up phase, has very few members, and is not yet able to manage the complexity of a microservice architecture.
- The company is creating a new, unproven product, or needs a proof of concept: if it is a new idea, it is likely that it will continue to evolve over time. A monolith is therefore ideal to enable a rapid product sequence. The same applies to a proof of concept, where the objective is to learn as much as possible and as quickly as possible, even if the project is discarded in the end.
- There is no previous experience with microservices: if the team has no experience with microservices, they should choose a monolith, unless the company is prepared to accept the risks of a “learning by doing” approach.
There’s nothing wrong with using microservices if…
- The company requires a faster and independent service delivery: microservices enable the rapid and independent provision of individual parts within a larger, integrated system.
- Part of the platform has to be efficient: this part should be built in a very efficient programming language. Different programming languages can be used for other components.
- The team is set to grow: those who start with microservices can ensure that the team is used to working in small, separate services from the very start. As the team grows, there is no need to exponentially introduce a greater degree of complexity, as the teams are already separated from one another by service boundaries.
A brief summary
Monolithic architectures aren’t facing extinction. However, microservices should be used according to the context. Companies should always think about their individual needs first, and then decide on the appropriate architecture.
Microservices Deep Dive
Microservices – multifaceted independence
The key features, characteristics and ultimately the advantages of microservices as well as of a microservices architecture consist in their independence from various points of view.
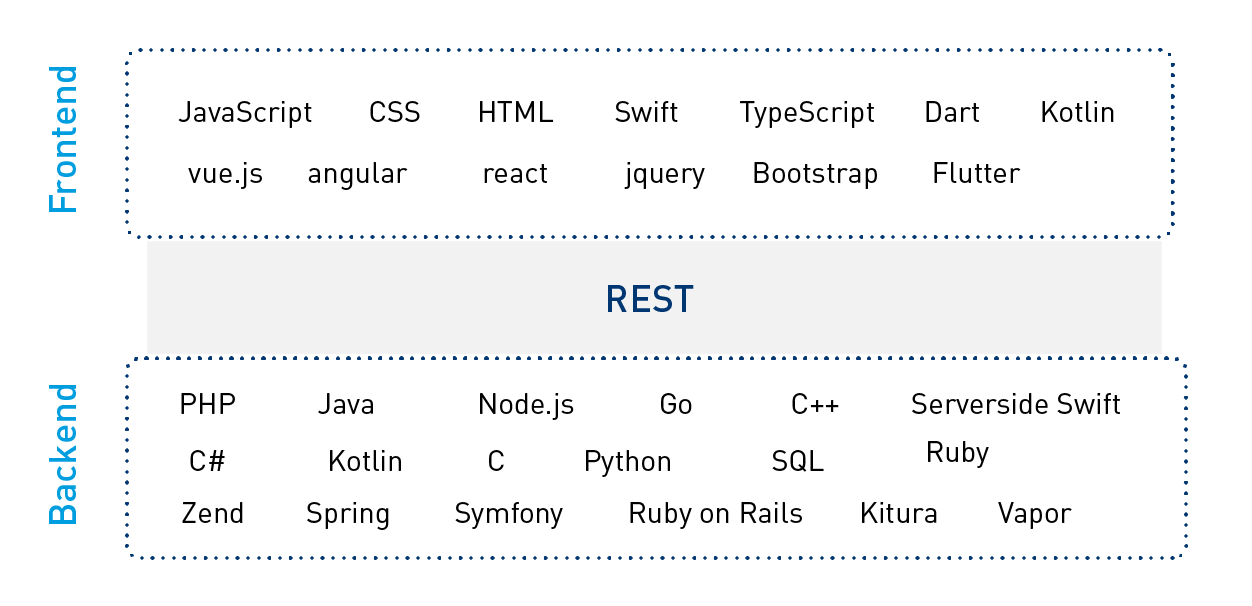
Technological freedom of choice 1: Microservices REST-Api
The programming language in which a client is written, and which interacts with the microservice, can be freely chosen. Because requests are often received via a REST API (REpresentational State Transfer), any programming language that supports REST can be used on the client side. REST is based on the HTTP verbs GET, PUT, POST/PATCH and DELETE, and is a very old network protocol. As far as the programming language for the clients is concerned, the choice is therefore yours. After all, whether a client for a microservice is Python-based or in any other language, is actually irrelevant as long as the client can handle REST and can address the REST API. The decision on the programming language in which a client for a microservice is written therefore depends on other factors.
Which protocols can still be used to address microservices on the client side?
REST is not the only API/protocol with which microservices can be addressed from the client. Some of the following examples are based on REST, extend it, and are also suitable for microservices:
- Open Data Protocol (oDATA): A protocol from Microsoft, also HTTP-based
- WebSockets: For communication in real-time, through a persistent connection between the client and service, without HTTP overhead and avoiding “long-polling”
- GraphQL: Query and API description language. Introduced by Facebook.
- RESTful API Modeling Language (RAML): Description language of APIs and their use.
- OpenAPI Specification: Standard for describing REST-compliant APIs; promoted by the OpenAPI initiative
Technological freedom of choice 2: Independence of the chosen programming language
There is also added freedom when implementing microservices. In principle, each microservice can be implemented in a different programming language. The decision on this must be made by the respective team that will implement and support the microservice. This also gives the teams considerably more freedom. After all, the question of which libraries, SDKs and databases etc. are chosen for a microservice is also decided by the teams. This is the only way to enable and maintain the independence and flexibility of microservices and to create the conditions for the accelerated deployment of the microservices (in this respect, also refer to Docker).
How do microservices actually communicate with one another?
After the client has transmitted data to a microservice via REST, the question that arises is what happens to it now? Within a microservice architecture, it is pretty obvious that the data also communicates with each other via APIs that are based on REST.
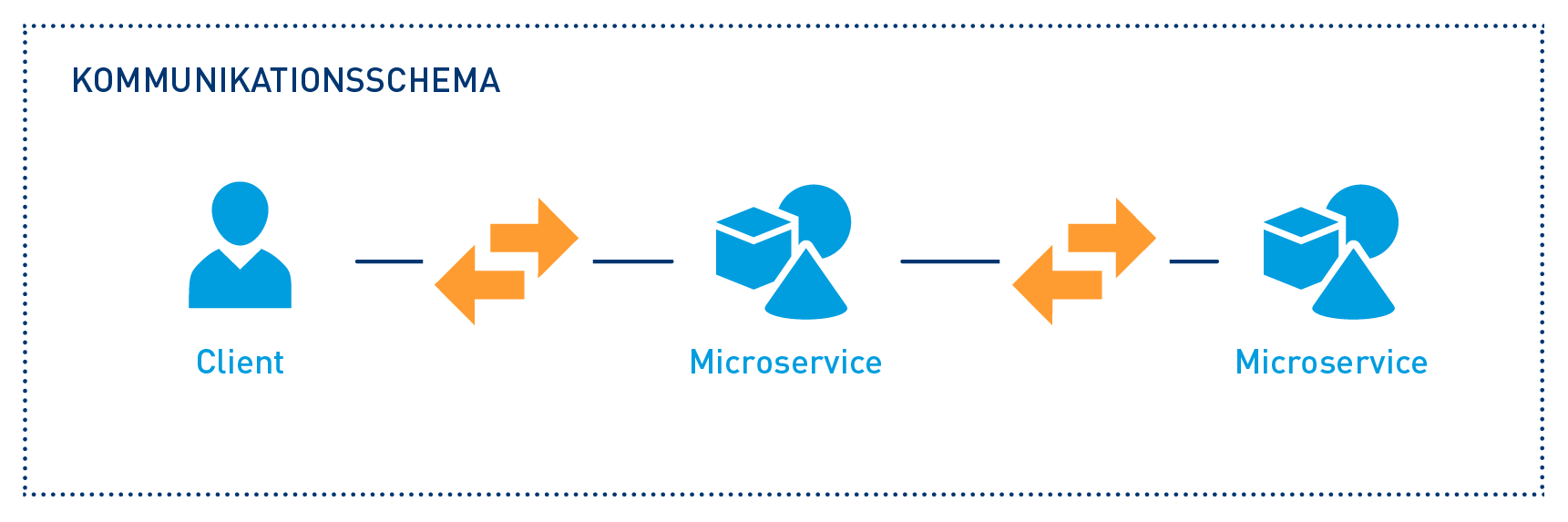
There are various approaches to this as well. Firstly, the most important things: The goal should always be the achievement of an asynchronous communication between the various microservices – in short: the use of ASYNC. Without going into further details, asynchronous communication at this point means, for example, that Microservice A sends its call to Microservice B – without waiting for the outcome of this request. At this point, A “only” receives the response code 202 (accepted), which is transmitted via HTTP header. A now “knows” that its request has been received and is being processed – with the outcome that the resources are freed up at A and other advantages are created, such as a lower degree of latency within the microservices architecture. The following protocols are then used as examples:
- RESTful (see above)
- OData (see above)
- Google Remote Procedure Calls (gRPC)
- Remote Procedure Calls (RPC)
- Thrift
The use of message queues, which to a certain extent constitute a separate message service, e.g. with RabbitMQ or Kafka, takes this ASYNC idea to the extreme. RabbitMQ, for example, works with special message protocols (AMQP, MQTT, STOMP). In this respect, correlation IDs are used to track which specific response message relates to which request.
Independent deployment of the microservices
Ideally, on the basis of previous considerations and decisions, the option to roll out a microservice independently of all the other services in the microservice architecture is now available. This describes the central strengths and characteristics of a microservice. Precisely because a microservice only completes one task, it ideally has a comparatively small code base, and can be rolled out and started comparatively quickly – and this service does not affect any other service in the microservices architecture. All other microservices remain available during the deployment and do not need to be re-deployed. To stay with the above example, the customer can continue to frank their shipments even though the microservice for the tracking of the shipment is currently being rolled out again.
This approach is therefore perfect for service-driven architectures. Useful to know: This division of microservices is also reflected in the responsibilities of the teams. Accordingly, DevOps teams can be formed, each of which specializes in a specific microservice – in this respect, the “Do one thing well” approach also applies to the teams (see: DevOps).
In comparison with a monolithic system, the advantages of a microservice architecture are obvious: Once the monolith is in operation, corresponding maintenance times must be scheduled for changes. After all, the structure means that the system is always affected entirely and may have to be restarted several times to test whether the changes in the code have the required effect. With a microservice architecture, this is not necessary. These new starts illustrate a further problem with monolithic structures: The more frequent the changes and the greater the amount of code, the slower the development process – and frequent changes are highly desirable when using MVPs via microservices, for example.
Microservices: Finely grained scalability
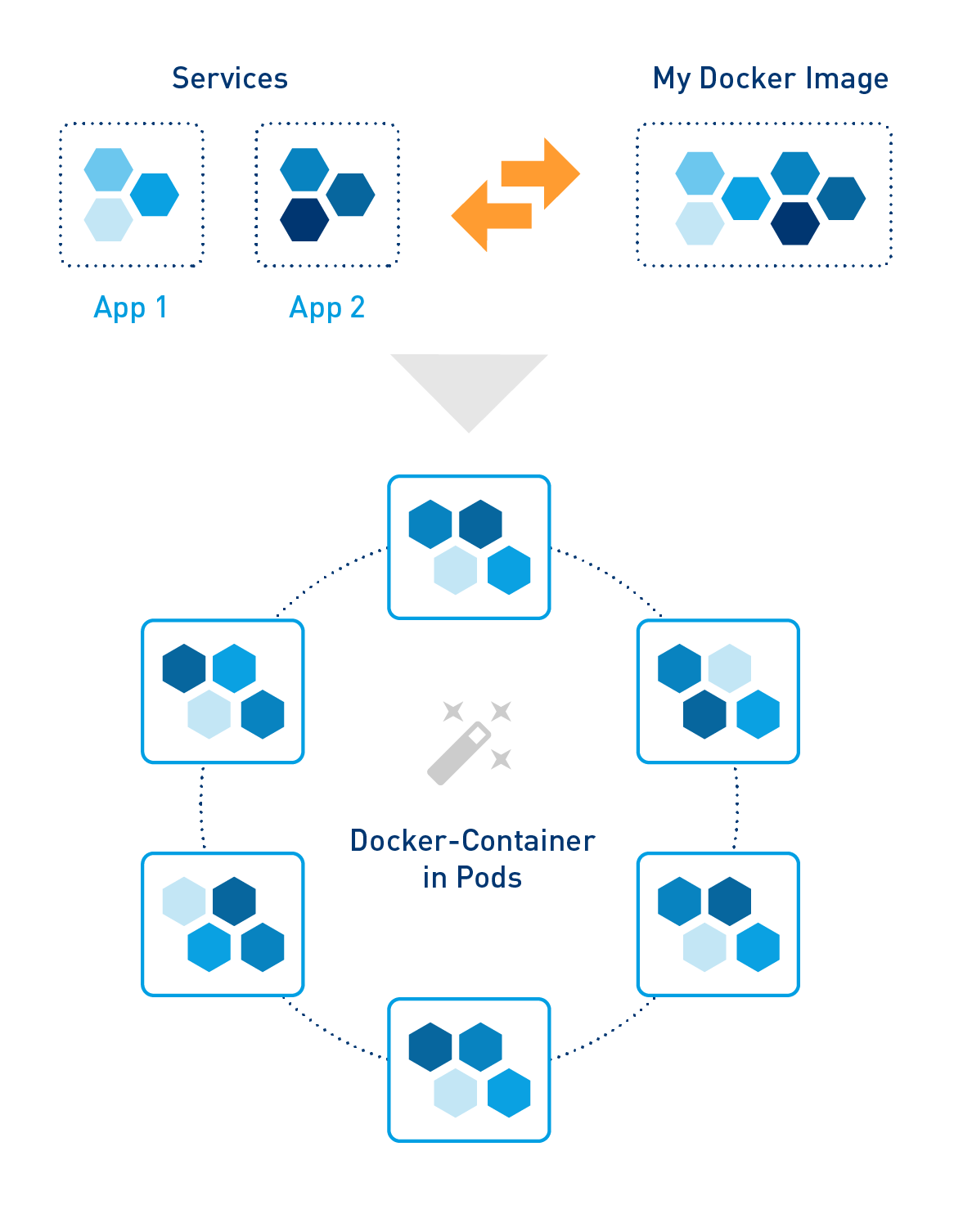
With the described segmentation, however, further advantages of the microservice architecture can be achieved in addition to the independent deployment. Once rolled out via Docker (see below), for example, managing the scalability of the individual services does not present the teams with any major challenges. If a microservice takes up too much CPU time or allocates too much memory, this can be compensated for pretty quickly by a load balancer and an additional microservice. With a monolith, the system always has to be scaled manually in its entirety.
All wrapped up: Microservices with Docker
Once packaged in narrow Docker containers (see below), nothing stands in the way of the rapid deployment of individual microservices. Due to the increased popularity of and enthusiasm for microservice architectures, in recent years, a toolchain for the software delivery process has developed.
For this purpose, various technologies are available to the individual microservices teams. Their goal: To automate the deployment process to a large extent and thereby simplify it. Saving time and avoiding mistakes is the motto.
Dockers and Kubernetes
Given the complexity of services which can have a microservices architecture, the DevOps team naturally requires the appropriate tools for the administration. Kubernetes (K8s) is one such tool. Imagine the initial situation: The basis of the architecture consists of several Docker containers and numerous hosts, i.e. individual physical or virtual computers. Using Kubernetes, the Docker containers can now be grouped, combined into pods and rolled out: on a node (vhost or physical computer), for example. In this context, the advantages of Kubernetes are the comparatively simple and rapid deployment of the microservices. At the same time, K8s offer a convenient solution for managing a microservice architecture with hundreds of microservices, for example: Balancing, scaling and monitoring peak loads. Dashboards (WebUI) and various command line tools are the tools of choice for managing the services on-premises, hybrid or in the public cloud – so they are perfect for DevOps managers to orchestrate the microservices. (Kubernetes is open source (Apache License 2.0))
Hybrid Cloud Solutions and AI – Future-proof IT Strategies for Companies
Maximize your business efficiency with the hybrid cloud and AI! The free whitepaper shows you how to process data efficiently and ensure security and compliance. Including a practical checklist for the right integration approach – read it now and get started!

Each new iteration of a microservice can then be rapidly introduced into the staging or production environment with the bug fixes and new enhancements, with low risk and little manual workload. Even for this area of software development, new methods and team structures and responsibilities are made use of, as wells as a new corporate culture, to a certain extent.
What is Docker?
Docker is considered a lightweight virtualization solution. Containers are the key element of Docker. Within these Docker containers, all the components belonging to a microservice (code, system tools and -libraries, etc.) can be zipped in an IMG file. The resources used on a computer are separated cleanly by Docker containers. As a container, the virtualization solution uses the kernel of the host, and in contrast to VirtualBox, VMware or XEN, does not come with its own kernel / operating system. Less RAM and time required to start the microservices are the result.
Continuous delivery, DevOps and microservices
To turn a noble goal into reality, it has proven to be best practice to make use of DevOps teams and the Continuous Delivery method. In combination with microservices, this trio constitutes a product of its age, with the keywords of “volatile markets/new challenges for companies/rapid provision of stable services”. Why is it that the requirements and goals outlined above can be achieved by this trio of microservices, DevOps and continuous delivery?
The word DevOps is a combination of the short forms of “Dev” for development and “Op” for operations – in this case: for IT operations. Software development, system administration and the deployment of microservices are now being considered simultaneously. The goal is a close cooperation between development and operation for the rapid provision of smoothly functioning microservices. The expertise of DevOps teams is to be found in software development AND in terms of IT systems and system infrastructure. In this way, DevOps combines the best of both worlds. In combination with the Continuous Delivery method, DevOps uses a tool chain, specific techniques and processes that automate and optimize the software deployment in terms of the software quality, flexibility and speed.
Releasing software is too often an art; it should be an engineering discipline.
David Farley
