

OCR-Technologie hilft uns bei der Texterkennung und erleichtert das Arbeitsleben enorm. Wofür man es benötigt und wie’s funktioniert, erfahren Sie hier.
Was ist Optical Character Recognition (OCR)?
Das OCR-Verfahren ist ein Text-Erkennungsprozess. In diesem Verfahren geht es darum, die dargestellten Buchstaben als solche zu erkennen. Dazu verwandelt der Prozess z.B. ein Dokument in ein Schwarz-weiß-Bild, also in eine Rastergrafik. Erst daraufhin folgt eine Mustererkennung.
Wie Optical Character Recognition jeden Tag hilft
Machen wir es praktisch. Anwendungsfälle für OCR existieren viele. Z.B. wenn jemand einen Vertrag oder eine Rechnung als PDF nicht nur lesen will. Enthalten diese PDFs nämlich auswählbaren Text,
- der sich ein anderes Dokument kopieren lässt oder
- ist das PDF bereits durchsuchbar,
hat häufig eine Zeichen- bzw. Texterkennung bereits stattgefunden. Das kennt fast jeder und ist nicht selbstverständlich. Denn oft bestehen PDFs nur aus Bilddaten. Texterkennung wird notwendig, da die dokumenterzeugenden Eingabegeräte wie Scanner, Faxgeräte oder digitale Kameras nur pixelbasierte Grafiken (JPEGs, PNGs, TIFFs etc.) ausliefern, eingebettet in ein PDF. Erst durch die Optical Character Recognition entstehen durch Mustererkennung Zeichen und Zeichenketten daraus.
Festzuhalten bleibt: Zeichenerkennung und das Umwandeln erkannter Zeichen in Text ist die Hauptaufgabe der Optical Character Recognition. Die Anwendungsfälle für die digitale Zeichenerkennung sind vielfältig, aber auf jeden Fall immer hilfreich.
Wo kommt OCR zum Einsatz?
Gerade im Kontext des automatisierten Dokumentenmanagements. Hier leistet die automatische Texterkennung wertvolle Dienste. OCR-Programme helfen z.B. bei der Gewinnung von Metadaten etc., die späterhin zur Verschlagwortung nutzbar sind. Anderes ist denkbar. Beispielsweise die Erkennung und Extraktion von Rechnungsdaten als Basis für den Three-way-Match. Im Grunde ist OCR für den gesamten Bereich der Belegerfassung essenziell.
Wie funktioniert OCR?
Die Grundlage, auf der das OCR-Verfahren zur Zeichenerkennung stattfindet, sind Rastergrafiken. Das sind in Zeilen und Spalten angeordnete Punkte unterschiedlicher Färbung, eben die einzelnen Pixel.
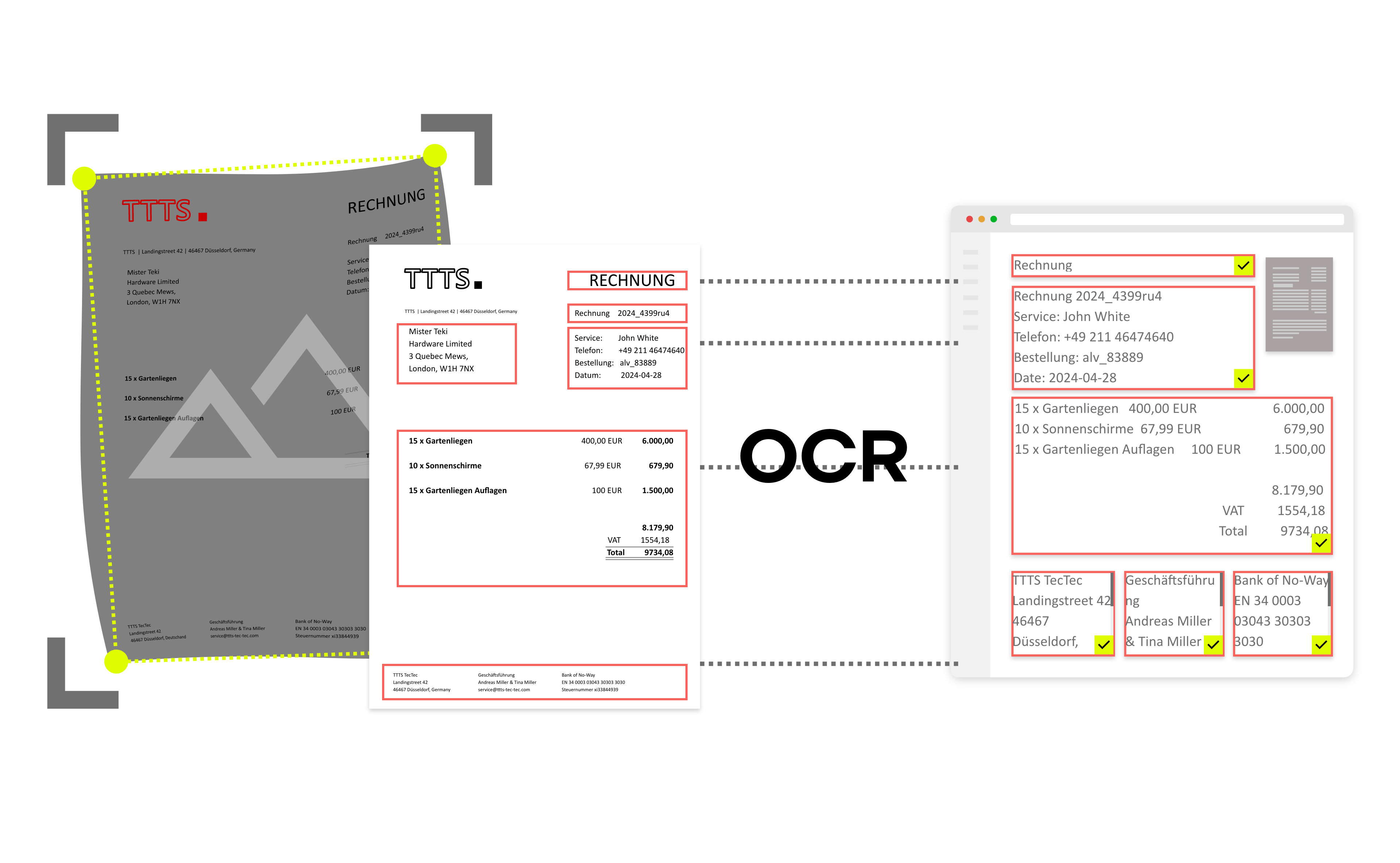
Optical Character Recognition ist eine Technologie, die dazu dient, gedruckte oder handgeschriebene Texte in maschinenlesbaren Text umzuwandeln.Der OCR-Prozess verläuft in mehreren Schritten:
- Bildaufnahme: Der erste Prozessschritt besteht darin, ein Bild oder einen Scan des Textdokuments zu erfassen.
- Vorverarbeitung: Das erfasste Bild wird vorverarbeitet, um es für das OCR und Texterkennung vorzubereiten. Dies kann das Entfernen von Rauschen, das Ausrichten von Text und die Anpassung des Kontrasts beinhalten.
- Segmentierung: Der Text wird in Segmente wie Textzeilen, Wörter oder Buchstaben unterteilt, um eine genauere OCR-Erkennung zu ermöglichen.
- Mustererkennung: In diesem Schritt analysiert der OCR-Algorithmus die Formen und Muster in den Segmenten, um Buchstaben, Zahlen und Symbole zu identifizieren.
- Textrekonstruktion: Die durch OCR erkannten Muster werden zu einem rekonstruierten Text zusammengesetzt.
- Textausgabe: Die rekonstruierten Textdaten stehen als Ausgabe zur Verfügung und können in einem digitalen Format gespeichert oder weiterverarbeitet werden.
Optical Character Recognition: Eine leistungsstarke Technologie zur Texterkennung
Auch wenn uns Akronyme aus dem IT-Kosmos oft schwer zugänglich erscheinen, so entfalten die damit verbundenen Technologien ihre Wirkmacht. Im Alltag hilft uns diese Technik, Texte aus Bildern oder Scans zu erfassen, zu bearbeiten und zu nutzen. So erspart uns Optical Character Recognition jede Menge Zeit und Mühen. Keiner muss mehr Texte abtippen oder zur Suche Absatz für Absatz durchlesen. Jeder der den PDF-Betrachter Adobe Acrobat nutzt, nutzt auch schon die dort eingebaute optische Texterkennung. Im professionellen Dokumentenmanagement und in dokumentenintensiven Prozessen ersetzt OCR die manuelle Dateneingabe. Dokumente lassen sich damit automatisch erfassen und klassifizieren, extrahieren und validieren. Wesentlich kürzere Bearbeitungszeiten bei gestiegener Datenqualität sind die Folge. Hier kommen OCR-Engines zum Einsatz, wie z.B. ABBYY Finereader oder Tesseract.

